Linux operating system is a popular choice for servers, logging of operating system, application, and base system events becomes crucial when hosting large commercial applications, Linux provides, multiple logging options, to help administrators and application support teams to record and track important events and assess the performance of he system and overall setup. here we will try to understand key logging features as made available by Linux OS
Linux Package Management
Linux provides multiple package management tools to simplify the process of package installation and upgrades, in this blog we look at RPM and YUM, and how they can be used for package management on Redhat flavour linux distributions
Load Average in Linux Servers – Confusion Solved
With Linux distributions acting as servers for majority of web applications and Software as a Service, Infrastructure as a Service, etc. platforms, managing Load on the installations is one of the most important tasks for system admins, SRE’s and technical support teams
How is Load measured
In linux load is measured in two dimensions
CPU Load : it is a measurement of CPU over / under utilization,
Load Average : it is the average system load over a period of time.
Lets see this in detail
Load Average can be found by running top command or uptime command as shown below

There are many misconceptions / doubts on how we understand the Load Average as shown in Linux
- What is load average as shown in top command ?
- What this values represent ?
- When it will be high, when low ?
- When to consider it as critical ?
- In which scenarios it can increase ?
In this Blog we will talk about the answers of all these .
What are these three values shown in above image ?
The three numbers represent averages over progressively longer periods of time (one, five, and fifteen-minute averages) and that lower numbers are better. Higher numbers represent a problem or an overloaded machine .
Now before getting into what is good value, what is bad value , what are the reasons which can affect these values , We will understand these on a machine with one single-core processor.
The traffic analogy
A single-core CPU is like a single lane of traffic. Imagine you are a bridge operator … sometimes your bridge is so busy there are cars lined up to cross. You want to let folks know how traffic is moving on your bridge. A decent metric would be how many cars are waiting at a particular time. If no cars are waiting, incoming drivers know they can drive across right away. If cars are backed up, drivers know they’re in for delays.
So, Bridge Operator, what numbering system are you going to use? How about:
- 0.00 means there’s no traffic on the bridge at all. In fact, between 0.00 and 1.00 means there’s no hold up, and an arriving car will just go right on.
- 1.00 means the bridge is exactly at capacity. All is still good, but if traffic gets a little heavier, things are going to slow down.
- over 1.00 means there’s holdup. How much? Well, 2.00 means that there are two lanes worth of cars total — one lane’s worth on the bridge, and one lane’s worth waiting. 3.00 means there are three lanes worth total — one lane’s worth on the bridge, and two lanes’ worth waiting. Etc.
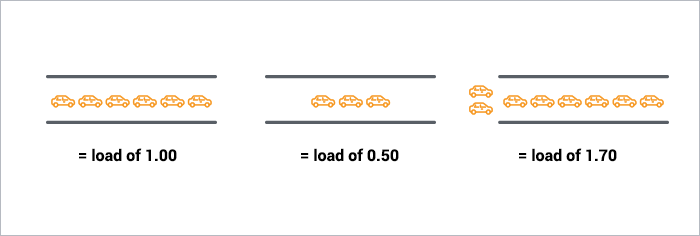
Like the bridge operator, you’d like your cars/processes to never be waiting. So, your CPU load should ideally stay below 1.00. Also, like the bridge operator, you are still ok if you get some temporary spikes above 1.00 … but when you’re consistently above 1.00, you need to worry.
So you’re saying the ideal load is 1.00?
Well, not exactly. The problem with a load of 1.00 is that you have no headroom. In practice, many sysadmins will draw a line at 0.70:
But now a days we many multiple cores systems or multiple processors system .
Got a quad-processor system? It’s still healthy with a load of 3.00.
On a multi-processor system, the load is relative to the number of processor cores available. The “100% utilization” mark is 1.00 on a single-core system, 2.00, on a dual-core, 4.00 on a quad-core, etc.
If we go back to the bridge analogy, the “1.00” really means “one lane’s worth of traffic”. On a one-lane bridge, that means it’s filled up. On a two-lane bridge, a load of 1.00 means it’s at 50% capacity — only one lane is full, so there’s another whole lane that can be filled.
Same with CPUs: a load of 1.00 is 100% CPU utilization on a single-core box. On a dual-core box, a load of 2.00 is 100% CPU utilization.
Which leads us to two new Rules of Thumb:
- The “number of cores = max load” Rule of Thumb: on a multicore system, your load should not exceed the number of cores available.
- The “cores is cores” Rule of Thumb: How the cores are spread out over CPUs doesn’t matter. Two quad-cores == four dual-cores == eight single-cores. It’s all eight cores for these purposes.
What if the load goes beyond the number of cores
But What to extract from here that if load is going beyond number of Cores , Are we in crunch of Cores ?
Well Not exactly , For this we need to further debug or analyse TOP command data to come to a conclusion.
Impact of User Process and System Process

In above output , This coloured part shows CPU used by
- user process(us) and
- system process(sy) .
Now if these values are around 99-100%, it means there is crunch of cpu cores on your system or some process is consuming more CPU . So, in this case either increase cores or optimize you application which is consuming more CPU .
Now let’s take another scenario :
Impact of disk read / write speed

In above image , coloured parts shows amount of time CPU is waiting in doing Input/Output(I/O) . So say if this values is going above say 80% ,then also load average on server will increase . It means either
- you disk read/write speed is slow or
- your applications is reading/writing too much on your system beyond system capability .
In this case either diagnose your hard disk read/write speed or check why your application is reading/writing so much .
Now let’s take one more scenario :
Impact of softirq’s

If values Above coloured output goes beyond certain limit , it means softirq(si) are consuming cpu. It can be due to network/disk interrupts . Either they are not getting enough CPU or there is some misconfiguration in you ethernet ports due to which interrupts are not able to handle packets receiving or transmitting . These types of problem occurs more on VM environment rather than physical machine.
Now , Lest take one last scenario :
Impact of CPU Steal Time

This above part will help you in case of Virtual Machine Environment .
If %st increases to certain limit say it is remaining more than 50% , it means that you are getting half of CPU time from base machine and someone else is consuming you CPU time as you may be on shared CPU infra . In above case also Load can increase .
Summary
I hope it covers all major scenarios in which load average can increase . Understanding different parameters from the output for top command can help you understand the performance of your linux server better.
Stay tuned to know more about further analyzing and answering questions like how to check read/write speed, how to check which application is consuming more CPU and how to check which interrupts are causing problem.
Refrences : https://scoutapm.com/blog/understanding-load-averages
See Original Posts at hello-worlds
and at medium
..
..
Author
Sahil Aggarwal
Senior Software Engineer 3/Tech Lead at Ameyo
I am a Tech Professional working in IT industry from 10 years . I have worked on many technologies like java, databases, linux, netrowking, security and lot more . I generally believe in taking outside-in approach to any new product you are looking for . This behaviour helped me lot in debugging issues of new products or even issues of any other system throughout by journey. I like to write tech blogs and I have my personal blog sites also, I write on medium and dzone also . I am very adaptive working between Individual Contributor and as a Leader/Manager. Apart from technology, I like eating fast and junk food . I also like to listen and write shyari.
Practical grep commands examples useful in real-world debugging
While troubleshooting any issue, log analysis is the most important step. Mostly the log files capture enormous amount of information, and reading those becomes a difficult and time consuming task. In our daily debugging we need to analyze logs files of various products.
Analyzing the logs to isolate and resolving the issues, can be complex and requires special debugging skills which are gained through experience or by god’s grace . During debugging we might need to extract some data from the log files, or we need to play with a log file which can not be done by just reading through the log file line by line , there is need for special commands to reduce the overall efforts and provide the specific information we seek.
There are many commands in linux which are used by debuggers like grep, awk, sed, wc, taskset, ps, sort, uniq, cut, xargs etc .
In this blog we will see some examples of practical usage of <strong>grep</strong>, useful in real world debugging in Linux . The examples which we will see in this blog are super basic but very useful in real life which a beginner should read to enhance the debugging skills
Grep (global search for regular expression and print out)</strong> is a linux command searches a file for a given pattern, and displays the lines which match the pattern. The pattern is also referred to as regular expression.
Let’s Go to the Practical Part.
Lets say we have a file “”file1.log””, which has following lines.
root@localhost playground]# cat file1.log
hello
i am sahil
i am software engineer
Sahil is a software engineer
sahil is a software engineerSearch the lines which contains some particular word
root@localhost playground]# grep 'sahil' file1.log
i am sahil
sahil is a software engineerSearch number of lines matched for a particular word in a file
grep -c 'sahil' file1.log
2Another way :
grep 'sahil' file1.log | wc -l
2Search all the lines which contains some word (case insensitive)
root@localhost playground]# grep -i 'sahil' file1.log
i am sahil
Sahil is a software engineer
sahil is a software engineerSearch the lines in which either of two words are present in a file
root@localhost playground]# grep 'sahil|software' file1.log
i am sahil
i am software engineer
Sahil is a software engineer
sahil is a software engineerSearch lines in which two words are present
root@localhost playground]# grep 'sahil' file1.log | grep 'software'
sahil is a software engineerSearch lines excluding some word
root@localhost playground]# grep -v 'sahil' file1.log
hello
i am software engineer
Sahil is a software engineerExclude words case insensitively
root@localhost playground]# grep -iv 'sahil' file1.log
hello
i am software engineerSearch the lines that start with a string
root@localhost playground]# grep '^sahil' file1.log
sahil is a software engineerSearch the lines that end with a string
grep 'engineer$' file1.log
i am software engineer
Sahil is a software engineer
sahil is a software engineerGetting n number of lines after each match
root@localhost playground]# grep 'hello' file1.log
hello
root@localhost playground]# grep -A 1 'hello' file1.log
hello
i am sahil
root@localhost playground]# grep -A 2 'hello' file1.log
hello
i am sahil
i am software engineerGetting n number of lines before each match
root@localhost playground]# grep 'i am sahil' file1.log
i am sahil
root@localhost playground]# grep -B 1 'i am sahil' file1.log
hello
i am sahil
root@localhost playground]# grep -B 2 'i am sahil' file1.log
hello
i am sahilin the second case only one line is printed as it is the only line before our pattern
Get n lines after and m lines before every match
root@localhost playground]# grep -A 2 -B 1 'i am sahil' file1.log
hello
i am sahil
i am software engineer
Sahil is a software engineerGet some word in more than one file in current directory
For this purpose we will assume we also have a second file “”file2.log”” in the same directory
root@localhost playground]# cat file2.log
hello
i am sahil
i am tech blogger
Sahil is a tech blogger
sahil is a tech bloggerGrep can be used to search in more than one file or within a directory
root@localhost playground]# grep 'sahil' file1.log file2.log
file1.log:i am sahil
file1.log:sahil is a software engineer
file2.log:i am sahil
file2.log:sahil is a tech bloggerGrep some word in all files in current directory
root@localhost playground]# grep 'sahil' *
file1.log:i am sahil
file1.log:sahil is a software engineer
file2.log:i am sahil
file2.log:sahil is a tech bloggerCheck how many lines matched in each file
root@localhost playground]# grep -c 'sahil' *
file1.log:2
file2.log:2
file.log:0Note : the above output signifies, we have a third file in the directory “”file.log””, but it has no lines that have a word “”sahil””
Grep using regular expression
Regular expressions are patterns used to match character combinations in strings
Suppose the content of files are as follows
root@localhost playground]# cat file3.log
time taken by api is 1211 ms
time taken by api is 2000 ms
time taken by api is 3000 ms
time taken by api is 4000 ms
time taken by api is 50000 ms
time taken by api is 123 ms
time taken by api is 213 ms
time taken by api is 456 ms
time taken by api is 1000 msNow suppose we want to grep all the lines in which time taken by any api is more than 1 second or more than 1000 ms , it means it should have minimum 4 digit number, grep command for this will be as follows
root@localhost playground]# grep -P '[0-9]{4} ms' file3.log
time taken by api is 1211 ms
time taken by api is 2000 ms
time taken by api is 3000 ms
time taken by api is 4000 ms
time taken by api is 50000 ms
time taken by api is 1000 msIf we want to get 5 digit number
root@localhost playground]# grep -P '[0-9]{5} ms' file3.log
time taken by api is 50000 msRecursively search in a directory and sub directories
root@localhost playground]# grep -R 'sahil' .
./dir1/file.log:i am sahil
./dir1/file.log:sahil is a software engineer
./file1.log:i am sahil
./file1.log:sahil is a software engineer
./file2.log:i am sahil
./file2.log:sahil is a tech bloggerAll above are basic use cases of grep . One can mix all the command options of grep to achieve the complex use cases and one can also mix different grep commands using pipe operator to achieve complex use cases
In future blogs we will explain some complex use cases and example how to achieve that using linux commands which can ease logs debugging.
Stay Tuned . . .
See Original Posts at hello-worlds
and at medium
and at dzone
..
Author
Sahil Aggarwal
Senior Software Engineer 3/Tech Lead at Ameyo
I am a Tech Professional working in IT industry from 10 years . I have worked on many technologies like java, databases, linux, netrowking, security and lot more . I generally believe in taking outside-in approach to any new product you are looking for . This behaviour helped me lot in debugging issues of new products or even issues of any other system throughout by journey. I like to write tech blogs and I have my personal blog sites also, I write on medium and dzone also . I am very adaptive working between Individual Contributor and as a Leader/Manager. Apart from technology, I like eating fast and junk food . I also like to listen and write shyari.
Top 10 network commands and their uses
Today every computer is connected to some other computer through a network whether internally or externally to exchange some information. This network can be small as some computers connected in your home or office, or can be large or complicated as in large offices or the entire Internet.
Maintaining a system’s network is a task of the System/Network administrator.
Here is a list of 10 Networking commands that must be known to the network administrator/tech support engineer
- ifconfig
- ip
- ping
- traceroute
- netstat
- telnet
- dig
- netcat
- nmap
- Wireshark
1. ifconfig
ifconfig, will be one of the most used commands and for a long time it was the default command used to configure and troubleshoot network interface and issues on linux, ifconfig is a command-line interface tool for network interface configuration and is also used to initialize interfaces at system boot time.
It is also used to view the IP Address, Hardware / MAC address, as well as MTU (Maximum Transmission Unit) size of the currently active interfaces.
Running ifconfig without any arguments, lists all the interfaces which are currently in operation
ifconfigTo list all interfaces which are currently available, whether up or down, use the -a flag
[centos@midas ~]$ ifconfig -a
enp3s0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 192.168.1.152 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::da72:6a96:b4cc:b4d6 prefixlen 64 scopeid 0x20<link>
ether 00:e0:4d:1e:b3:1c txqueuelen 1000 (Ethernet)
RX packets 1443 bytes 111527 (108.9 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 124 bytes 10010 (9.7 KiB)
TX errors 8 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 144 bytes 12836 (12.5 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 144 bytes 12836 (12.5 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
wlp0s20u6: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.29.22 netmask 255.255.255.0 broadcast 192.168.29.255
inet6 fe80::6ebc:877a:f6c0:885c prefixlen 64 scopeid 0x20<link>
inet6 2405:201:4019:91a2:d7c7:e3b2:ae40:468a prefixlen 64 scopeid 0x0<global>
ether 3c:33:00:60:48:f8 txqueuelen 1000 (Ethernet)
RX packets 551536 bytes 105040791 (100.1 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 51404 bytes 5621067 (5.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Viewing the configuration of a specific interface
[centos@midas ~]$ ifconfig enp3s0
enp3s0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 192.168.1.152 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::da72:6a96:b4cc:b4d6 prefixlen 64 scopeid 0x20<link>
ether 00:e0:4d:1e:b3:1c txqueuelen 1000 (Ethernet)
RX packets 1443 bytes 111527 (108.9 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 124 bytes 10010 (9.7 KiB)
TX errors 8 dropped 0 overruns 0 carrier 0 collisions 0
Configuring an interface
[root@midas ~]# ifconfig enp3s0 192.168.1.122 netmask 255.255.255.0 broadcast 192.168.1.255
[root@midas ~]# ifconfig enp3s0
enp3s0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 192.168.1.122 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::da72:6a96:b4cc:b4d6 prefixlen 64 scopeid 0x20<link>
ether 00:e0:4d:1e:b3:1c txqueuelen 1000 (Ethernet)
RX packets 1443 bytes 111527 (108.9 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 124 bytes 10010 (9.7 KiB)
TX errors 8 dropped 0 overruns 0 carrier 0 collisions 0
2. IP
The IP command is the new default networking command for linux and has replaced ifconfig, it is a part of iproute2util package. IP command takes different flags and syntax than if config command. The ip command is more versatile and technically more efficient than ifconfig because it uses Netlink sockets, though the syntax can be more complex than ifconfig
To list all the all the interfaces we can use “”ip addr show”” or “”ip a”” for short
[root@midas ~]# ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp3s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000
link/ether 00:e0:4d:1e:b3:1c brd ff:ff:ff:ff:ff:ff
inet 192.168.1.122/24 brd 192.168.1.255 scope global noprefixroute enp3s0
valid_lft forever preferred_lft forever
inet6 fe80::da72:6a96:b4cc:b4d6/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: wlp0s20u6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 3c:33:00:60:48:f8 brd ff:ff:ff:ff:ff:ff
inet 192.168.29.22/24 brd 192.168.29.255 scope global dynamic noprefixroute wlp0s20u6
valid_lft 15969sec preferred_lft 15969sec
inet6 2405:201:4019:91a2:d7c7:e3b2:ae40:468a/64 scope global dynamic noprefixroute
valid_lft 3596sec preferred_lft 3596sec
inet6 fe80::6ebc:877a:f6c0:885c/64 scope link noprefixroute
valid_lft forever preferred_lft forever
Add IP address
[root@midas ~]# ip a add 192.168.1.152/24 dev enp3s0
[root@midas ~]# ip a show enp3s0
2: enp3s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000
link/ether 00:e0:4d:1e:b3:1c brd ff:ff:ff:ff:ff:ff
inet 192.168.1.122/24 brd 192.168.1.255 scope global noprefixroute enp3s0
valid_lft forever preferred_lft forever
inet 192.168.1.152/24 brd 192.168.1.255 scope global secondary noprefixroute enp3s0
valid_lft forever preferred_lft forever
inet6 fe80::da72:6a96:b4cc:b4d6/64 scope link noprefixroute
valid_lft forever preferred_lft forever
Enable or disable a network
ip commands uses the set sub command for this operation
ip link set enp3s0 up
ip link set enp3s0 down3. Ping
Ping is a simple, widely used, cross-platform networking utility for testing if a host is reachable on an Internet Protocol (IP) network. It works by sending a series of Internet Control Message Protocol (ICMP)
ping is a very common and relatively simple command, but it also provides there are some great options and techniques that make the tool even better, to troubleshoot connectivity issues
[root@midas ~]# ping 192.168.29.1
PING 192.168.29.1 (192.168.29.1) 56(84) bytes of data.
64 bytes from 192.168.29.1: icmp_seq=1 ttl=64 time=1.59 ms
64 bytes from 192.168.29.1: icmp_seq=2 ttl=64 time=2.00 ms
64 bytes from 192.168.29.1: icmp_seq=3 ttl=64 time=1.30 ms
64 bytes from 192.168.29.1: icmp_seq=4 ttl=64 time=1.49 ms
^C
--- 192.168.29.1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3004ms
rtt min/avg/max/mdev = 1.303/1.592/1.995/0.253 ms
ping -a <host>, adds audible cue, giving a system sound whenever the pings are successful
ping -c <host>, lets you adjust the number of pings
ping <hostname> also lets you display the ip address of the hostname
Output from ping
- ping output provides some useful insights into the quality of the network, the most important metrics are packet loss, time,
- whether the target host is reachable (active) or not,
- to measure the amount of time it takes for packets to get to the target host and back to your computer
- the packet loss, expressed as a percentage.
- timeout message indicates that your machine believes it sent successful ping queries to the destination but it did not receive the replies in the specified time
- TTL means “”time to live””. It is a value on an ICMP packet and this value is decreased every time a router touches the packet. If the TTL ever reaches zero, the packet is discarded. It is a measure of the number of hops the packet took to reach the destination, if your initial value was 64 and now you see a value of 28 there are 36 hops between the originated and final destination
- Time metric can also be used to assess the quality of the network and it provides insights into latency and jitter in the network, a high response time signifies high latency, where as a fluctuating time value in response signifies jitter.
4. Traceroute
Traceroute is a command-line utility for tracing the full path from your local system to another network system. It prints a number of hops (router IPs) in that path you travel to reach the end server. It is an easy-to-use network troubleshooting utility after the ping command
5. Netstat (network statistics)
netstat (network statistics) is the command-line tool for monitoring network connections both incoming and outgoing as well as viewing routing tables, interface statistics, etc. It can be used for troubleshooting and for configuration.
Listing all ports
Note : we have used more to control the output, it is not necessary
[root@midas ~]# netstat -a | more
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 localhost:ipp 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN
tcp 0 96 midas.upspiroffice.:ssh 192.168.29.147:53980 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
tcp6 0 0 localhost:ipp [::]:* LISTEN
udp 0 0 0.0.0.0:mdns 0.0.0.0:*
udp 0 0 0.0.0.0:47053 0.0.0.0:*
udp 0 0 midas.upspiroffi:bootpc reliance.relianc:bootps ESTABLISHED
udp 0 0 localhost:323 0.0.0.0:*
udp6 0 0 [::]:mdns [::]:*
List only TCP port connections
For listing only TCP (Transmission Control Protocol) port connections using netstat -at.
[root@midas ~]# netstat -at
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 localhost:ipp 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN
tcp 0 288 midas.upspiroffice.:ssh 192.168.29.147:53980 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
tcp6 0 0 localhost:ipp [::]:* LISTEN
[root@midas ~]#
Listing all active listening ports netstat -l
Listing all active listening UDP ports by using option netstat -lu
Showing network interface packet transactions including both transferring and receiving packets with MTU size
[root@midas ~]# netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
enp3s0 1500 133 0 0 0 38 5 0 0 BMRU
lo 65536 44 0 0 0 44 0 0 0 LRU
wlp0s20u6 1500 844 0 0 0 198 0 0 0 BMRU
6. Telnet
Telnet command is used to establish the connections between different machines. This command allows us to manage the remote devices using the CLI (command-line interface)
Open a connection with a remote host
[root@localhost centos]# telnet 192.168.1.22 80
Trying 192.168.29.22...
Connected to 192.168.29.22.
Escape character is '^]'.
If no port is specified, it uses TCP port 23 which is assigned to the telnet protocol
7. Nslookup
tool for testing and troubleshooting DNS servers (Domain Name Server). It is used to query specific DNS resource records (RR) as well
8. Dig (Domain Information Groper)
just like nslookup command, this command is used for querying and getting information of DNS (Domain Name System).
Dig stands for (Domain Information Groper) is a network administration command-line tool for querying Domain Name System (DNS) name servers.
[root@localhost centos]# dig yahoo.com
; <<>> DiG 9.16.23-RH <<>> yahoo.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 26615
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 6, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;yahoo.com. IN A
;; ANSWER SECTION:
yahoo.com. 561 IN A 74.6.231.21
yahoo.com. 561 IN A 74.6.231.20
yahoo.com. 561 IN A 74.6.143.25
yahoo.com. 561 IN A 98.137.11.163
yahoo.com. 561 IN A 98.137.11.164
yahoo.com. 561 IN A 74.6.143.26
;; Query time: 2 msec
;; SERVER: 192.168.29.1#53(192.168.29.1)
;; WHEN: Thu Sep 29 15:27:37 IST 2022
;; MSG SIZE rcvd: 123
Dig command reads the /etc/resolv.conf file and querying the DNS servers listed there
To query domain “A” record with +short
[root@localhost centos]# dig yahoo.com +short
98.137.11.164
74.6.143.26
74.6.231.21
74.6.231.20
74.6.143.25
98.137.11.163
9. Netcat
Netcat (or nc in short) is a simple yet powerful networking command-line tool used for performing any operation in Linux related to TCP, UDP, or UNIX-domain sockets.
Netcat can be used for port redirection, as a port listener (for incoming connections); it can also be used to open remote connections and so many other things. Besides, you can use it as a backdoor to gain access to a target server.
Here is an example, the -z option sets nc to simply scan for listening daemons, without actually sending any data to them. The -v option enables verbose mode and -w specifies a timeout for connection that can not be established.
10. Nmap
Network Mapper is an open-source and a very versatile tool for Linux system/network administrators. Nmap is used for exploring networks, performing security scans, network audit,s and finding open ports on the remote machine
Nmap allows you to scan your network, to discover not only what is connected to it but also a host of other information like what devices are listening on which ports, it comes with a large number of scanning techniques and filters.
Scan a System with Hostname and IP Address
to find out all open ports, services and MAC addresses on the system.
nmap hostname
nmap ipaddress[root@midas centos]# nmap 192.168.29.44
Starting Nmap 7.91 ( https://nmap.org ) at 2022-09-29 15:42 IST
Nmap scan report for 192.168.29.44
Host is up (0.021s latency).
Not shown: 997 filtered ports
PORT STATE SERVICE
22/tcp open ssh
2049/tcp open nfs
MAC Address: 80:86:F2:47:E4:C4 (Intel Corporate)
Nmap done: 1 IP address (1 host up) scanned in 10.53 seconds
….
…..
Author
Pravin Tewari
Senior Manager, Application and Cloud Support
Pravin is a visionary professional with over 11 years of experience in Technical Support, Cloud Infrastructure Management, and Customer Experience. He has hands-on experience in working across the lifecycle of project delivery and deployment, solution consulting, and support. He has deep experience in managing cloud deployments and implementing DevOps tools for automation to provide better uptime. Pravin has successfully led large product & cloud support teams, and coached & mentored a high-performing team that delivers high-quality service to customers.